MySQL이 조금은 달라졌다
2024.10.28
모처럼 Vim 배우겠다고 이런저런 리소스를 찾아보다가, 잠깐 옆길로 새서 MySQL에서 'a' = 'a '라는 식이 참으로 평가되고, 왜 그렇게 되는지를 설명한 글을 읽었습니다. 읽어보고 흥미로운 내용이라고 생각해서 친구에게 공유했는데, 그네는 곧바로 자신의 로컬 MySQL에서 해당 쿼리를 실행해보고 결과랑 정 반대로 나온다며, 써진지 6년이 된 글을 곧이곧대로 퍼오면 어떡하냐며 저를 일갈합니다.
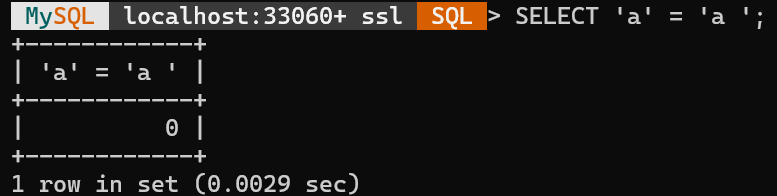
로컬에 MySQL 8.0.40이 설치되어 있으니, 바로 실행해서 확인해보면 좋았을텐데 역시 세상은 새 발의 피도 닦는 사람이 바꿉니다. 귀찮아서 링크만 바로 보냈더니 이런 일이 일어납니다. 그렇게 혼나고 나서 로컬에서 확인해보니 진짜 거짓으로 평가합니다. 상기 식이 참으로 평가되던 때 MySQL의 버전은 5.6입니다. MySQL에 어떤 변화가 일어나서 이런 차이가 생기는 걸까요.
글의 본문 중, '책을 찾아보자' 단락에서는 "문자열 비교방식 때문에 그렇다"고 언급하고 있습니다. 길이가 같지 않은 CHAR 자료형에 대해서는 공백을 집어넣어 동일한지를 비교한다(했다)는 것입니다. 이를 PAD SPACE 방식이라고 합니다. 현재는 NO PAD 방식으로 문자열을 비교하기 때문에 8.0.40 버전의 MySQL에서는 글이 거짓으로 평가됩니다.
즉, 문자열의 비교 방식이 바뀌었습니다. 최근 버전의 MySQL에서는 더이상 공백을 붙여 비교하지 않습니다.
비교 방식 Collation
공식 문서 설명 비교 방식은 MySQL이 문자열에 대해 비교 연산을 진행할 때 그것의 결과에 대해 무엇을 더 크다고 판단하는지를 정의한 것입니다.ORDER BY절이나 WHERE절에서 문자열이 같은 지를 검사하는 행위 등에서 사용합니다. 데이터베이스 시스템은 다양한 문자를 지원하면서도 연산이 항상 동일한 결과를 반환하고, 사용자가 익숙한 순서에 경과를 반환하도록 비교 방식을 반드시 정해야 합니다. 사용자가 익숙한 순서란 우리가 흔히 어떤 언어의 문자(writing)를 배우면서 그것의 원어 화자가 기대하는 순서를 의미합니다. 한국인은 책을 제목으로 정리한다면 기역-니은-디귿-리을 및 아야어여오요 순으로 순서를 세우겠습니다. 일본인은 あいうえお, かきくけこ, ... 순으로 정렬할 것입니다. 기본 로마자에 다이어크리틱을 도입하여 문자로 삼는 유럽 국가도 자신들의 문자에 대해 순서를 정해놓습니다. 이런 것을 정의한 것이 비교 방식, Collation입니다.
유니코드에 대한 비교 방식은 UCA(Unicode Collation Algorithm)을 기반으로 두고있습니다. 상기된 각 언어에서 관습적으로 사용하는 정렬 방식이 정의되어있습니다.
즉, MySQL은 문자열을 비교해야 할 때는 문자열 집합에 대해 정의된 비교 방식(Collation) 사용합니다.
패드 속성 Pad attribute
이와 더불어 MySQL에서는 Collation이 정의하는 것이 하나 더 있습니다. 패드 속성이라고 부르는 것입니다. 이는 넌바이너리 문자열(non-binary string)을 비교할 때, 주어진 문자열 끝에 붙은 공백 문자 취급을 정의합니다. 방법은 두 가지로 나뉩니다.- NO PAD: 공백 문자도 비교에 사용합니다.
- PAD SPACE: 공백 문자를 비교에 사용하지 않습니다.
지금 쓰는 문자세트 확인하기
SHOW VARIABLES LIKE 'character%';을 하면 서버의 시스템 변수 중 문자 세트와 관련된 변수를 확인할 수 있습니다. 관련 내용은 이곳을 참조할 수 있습니다.
character_set_client: 클라이언트가 보낸 질의문에 사용되는 문자 세트를 정의합니다.--default-character-set을 통해 클라이언트 측에서 설정 가능합니다.character_set_connection: 문자 집합 소개자(Character set introducer)을 사용하지 않은 리터럴과 문자열로 변환되는 수에 대하여 사용하는 문자 세트- 문자 집합 소개자: 문자열 리터럴에 대해 특정 문자 세트를 쓰도록 설정할 수 있는 부분 구문입니다. 더 자��세한 내용은 이곳을 참조할 수 있습니다.
character_set_database: 디폴트 데이터베이스가 사용하는 문자 세트를 정의합니다.character_set_results: 클라이언트에게 질의문 실행 결과를 반환할 때 사용하는 문자 세트를 정의합니다.character_set_server: 서버가 사용하는 디폴트 문자 세트를 정의합니다.
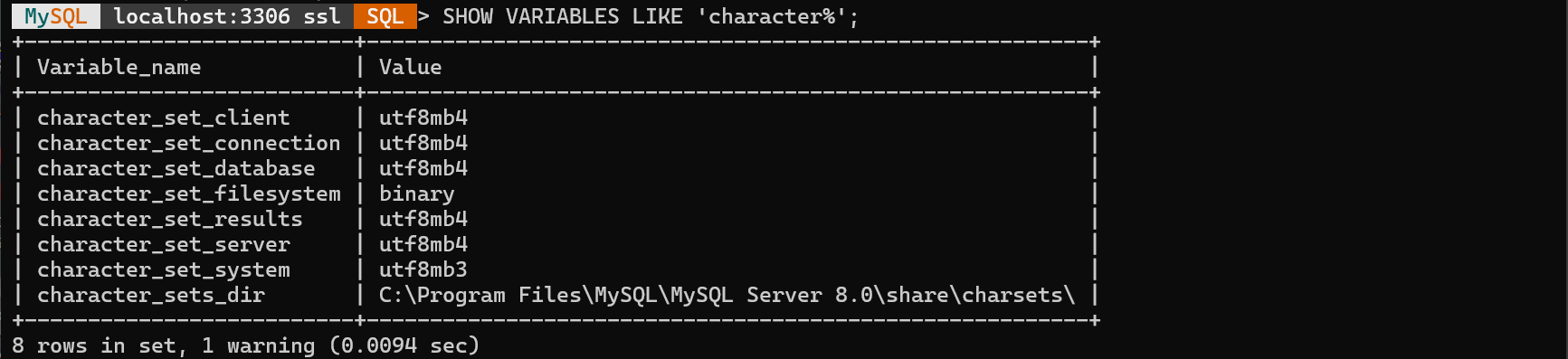
VALUE 컬럼에서 character_set_server의 디폴트 문자 세트를 확인합니다. 값은 utf8mb4가 나왔습니다.
지금 쓰는 비교 방식 확인하기
SHOW VARIABLES LIKE 'collation%';은 각 상황에서 사용하는 Collation을 확인할 수 있습니다. 관련 항목으로는 collation_connection, collation_database, collation_server가 있습니다.

VALUE 컬럼에서 collation_server의 디폴트 Collation을 확인합니다. 값은 utf8mb4_0900_ai_ci가 나왔습니다.
비교 방식의 패드 속성 알아보기
INFORMATION_SCHEMA.COLLATIONS에서는 각 문자 세트와 그것이 사용하는 COLLATION에 관련된 사항을 알아볼 수 있습니다. 특히 Pad attribute 컬럼에서는 비교 방식에 공백을 더하는지를 알아볼 수 있습니다.

PAD_ATTRIBUTE 컬럼에서 utf8mb4_0900_ai_ci의 패드 방식을 확인합니다. NO PAD입니다. 즉, 공백 문자도 비교에 사용하기 때문에 상기 문자열의 동치검사를 하면 거짓이 출력됩니다.
요약
문자열 비교 방식이 바뀌었습니다. 본래 공백을 붙여 길이를 같게 한 다음 비교하는 방식에서 Collation이 추가되며 기본으로 사용되는 비교 방식은 더이상 공백을 붙이지 않습니다. 따라서 거짓을 반환합니다.